

How Does a Scrapper API Help You Acquire Real-Time Data Using Python?

In today's fast-paced world of data-driven decision-making, swift adaptation to changes is critical. Whether you're a corporation attempting to remain ahead or an individual looking to stay competitive, having real-time data is critical. The Scraper API is a powerful tool that speeds up and simplifies the process of scraping data from websites.
Instead of doing things the traditional way, which may mean by hand or with advanced computer code, Scraper APIs perform all of the work for you. It simplifies and speeds up the entire procedure, allowing you to acquire the most up-to-date information without fuss. In the data-driven era, real-time API emerges as a vital instrument in the pursuit for strategic advantage and informed decision-making by automating the data extraction process and providing a consistent stream of real-time information.
What is Real-Time Data?
Real-time data refers to information that is processed and made available immediately, with no obvious delay or latency. In computer and information systems, real-time data is data that is created, processed, and provided in a near-instantaneous or extremely short time frame.
Real-time data is critical in a variety of fields, particularly as we increasingly rely on data-driven decisions. Seeing and interpreting information instantly provides you an advantage, especially in areas where rapid answers and insights are essential.
Here Are Some Key Characteristics And Features Of Real-Time Data:- Immediate Availability Imagine you had a magical book that updates itself whenever something new happens. Real-time data is similar to a magic book in that it provides information immediately, without waiting. If a cat leaps, you know it leaped immediately, not after a pause
- Lower Latency Latency refers to the time it takes for communication to go from one buddy to another. In real-time data, this time is extremely brief. Real-time data API systems provide you with information very rapidly.
- Continuous Updates Think of real-time data as a never-ending story that keeps getting new chapters. It’s a news feed that never stops. As things change around you, the information you see is updated instantly.
- Dynamic and Changing Real-time data assists things that move and change a lot. Whether it’s the stock market, social media, or sensors measuring things, real-time data API catches every move and change as it occurs.
Examples of Real-Time Data:
- Stock market prices and trades.
- Social media updates and interactions.
- Traffic and weather updates.
- Sensor readings from IoT (Internet of Things) devices.
- Online gaming interactions.
What is a Scraper API?
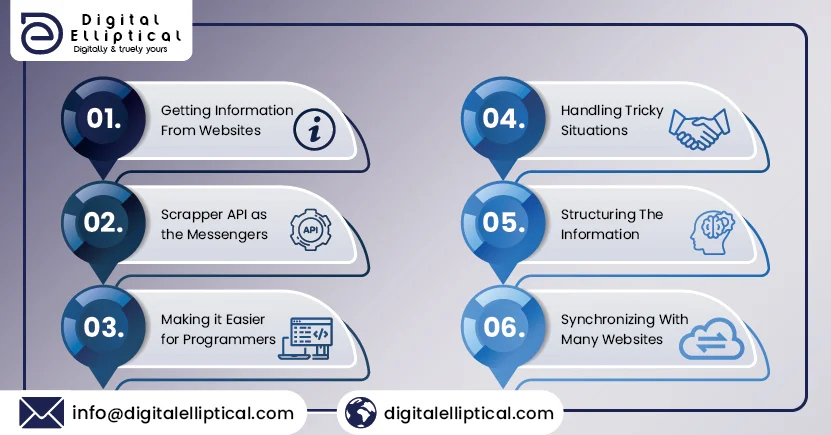
A Scraper API, or Application Programming Interface, bridges the communication gap between computer programmer and websites. Let's look at the components of the Scraper API that are important for every business:
- Getting Information from Websites: Imagine you have a robot friend that can read information from websites. This robot friend is your program, and it needs a way to communicate with websites and collect data, like prices, news, or weather updates.
- Scraper API as the Messenger: It helps your program ask the website for specific information and brings back the answers. It works as your robot friend sending a message to a website and getting a reply with the details you’re interested in.
- Making it Easier for Programmers: Using a Scraper API makes things much more accessible for people who write programs (programmers). It’s a special tool that understands the language of websites and helps your program grab the data without you having to write a lot of complicated code.
- Handling Tricky Situations Sometimes, websites have locks or challenges (like puzzles) to keep robots out. The Scraper API is smart and knows how to deal with these challenges.
- Structuring the Information After the Scraper API gets the information from the website, it helps organize it neatly. It also formats the information into a desired format.
- Synchronization with Many Websites: Different websites may have different ways of talking, like people speaking different languages. The Scraper API is like a robot friend being multilingual – it knows how to communicate with various websites, making it versatile and able to fetch data from many different places.
How to Scrape Real-time Data with Scraper API
Businesses can scrape real-time data with real-time API by following predetermined steps by utilizing the Python libraries:
- The first thing we need to do is install the essential libraries for the scraping, namely BeautifulSoup and Selenium. pip install bs4 pip install selenium
- To make a basic distinction, we will require Selenium to visit a website, interact with the browser by clicking buttons, and wait for components to appear. The real data is extracted using BeautifulSoup, which iterates across the HTML.
- As a result, commencing scraping straight with Beautiful Soup will result in no entries because the data must first be in the HTML. We fix this problem by adding a listener to the element that is formed once the data is retrieved. By right-clicking and pressing the “Inspect Element” button on the page, we can see in the inspection interface that the element to wait for is the class “name”.
-
To scrape a webpage, the Selenium library requires the
Google Chrome browser (but you may use any browser). We,
therefore, instruct Selenium to start Google Chrome.
From selenium import webdriver driver = webdriver.Chrome(ChromeDriverManager().install()) and inform the driver where our website is by supplying the URL. driver.get(“https://severeweather.wmo.int/v2/list.html”) -
Now, we can configure the listener stated above to allow the
driver to wait for the element with dataTables_scrollBody
class to appear in the HTML.
try:elem = WebDriverWait(driver, 30).until( EC.presence_of_element_located((By.CLASS_NAME, “dataTables_scrollBody”))). finally: print(‘loaded’) -
We name our scraping function as scrapeWeather, and our code
should look like this:
### imports import pandas as pd
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from webdriver_manager.chrome import ChromeDriverManager ###
def scrapeWeather(): # Our function for scraping
driver = webdriver.Chrome(ChromeDriverManager().install())
#url request
driver.get(“https://severeweather.wmo.int/v2/list.html”)
try:
elem = WebDriverWait(driver, 30).until( EC.presence_of_element_located((By.CLASS_NAME, “dataTables_scrollBody”)))
finally: print(‘loaded’) - Now that the data is in HTML, we can use BeautifulSoup to scrape specific entries.
-
The examination reveals that the tag contains all of the
data. Each tag represents one row in the table. Thus, we
must identify the right and begin looping over all of its
tags. This is accomplished using the method findAll, which
returns all of the HTML tag’s entries.
soup = BeautifulSoup(driver.page_source, ‘html.parser’) “””Scraper getting each row””” all = soup.findAll(“tbody”)[2] #the we want is the third one row = all.findAll(‘tr’) -
We will save the entries to a CSV file. To populate the
array with data from each row of the table, loop over each
row (i) and column (j) and store the information to the
appropriate variable. The code will look like this:
rest_info = [] # empty array populated with the info of each
row
for i in rows: #i is a row
infos_row = i.findAll(‘td’) # get the info of a single row
for index, j in enumerate(infos_row): #j is a col of row i info = None
if index == 0: #in this case the first col has the event information
info = j.find(‘span’) #the info is within a span
event = info.text #we extract the text from the span
if index == 4:
info = j.find(‘span’)
areas = info.text
if index == 1:
issued_time = j.text
if index == 3:
country = j.text
if index == 5:
regions = j.text
if index == 2:
continue
#finally we append the infos to the list (for each row) rest_info.append([event,issued_time,country,areas,regions)]) -
Now that we’ve stored the information in the list, we’ll
export it as a CSV.
df = pd.DataFrame(rest_info, columns= [‘Event_type’,’Issued_time’,’Country’,’Areas’,’Regions’,’Date’]) df.to_csv(“scraped_weather.csv”,mode=’a’, index=False,header=False)
The CSV file should look like the following:
Why Use Scraper API to Acquire Real-Time Data?
A Scraper API is a useful tool for extracting real-time data from websites. Let's see why firms utilise a Scraper API for real-time data scraping.
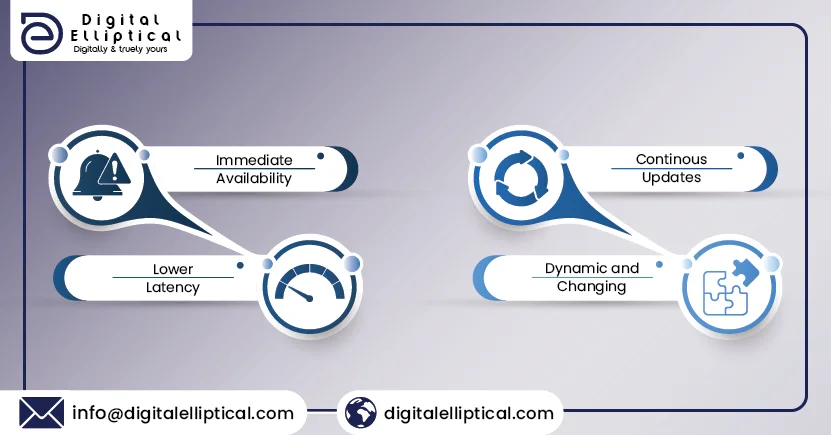
- Immediate Access to Data A Scraper API provides quick access to data as it is created or changed on a website. It serves as a quick messenger between your application and the target website, ensuring that there is no delay between the occurrence of an event on the website and your ability to obtain the relevant data.
- sLow-latency communication A Scraper API reduces latency, or the time it takes for data to move from a website to your application, to an absolute minimum. This guarantees that the information you receive represents the most recent state of things on the website. The API streamlines communication, lowering the time required to retrieve real-time changes.
- Continuous and automatic updates Continuous changes distinguish real-time data, and Real-time APIs excel at automating this process. The API scans the website for new information regularly, and when there are updates, it automatically collects and transmits the most recent data to your application. This continual updating system guarantees you are constantly dealing with the most current information.
- Handling Dynamic, Changing Content Many websites use dynamic Content, which often involves changing parts using technology such as JavaScript. A Real-time API is specifically built to handle such dynamic material, guaranteeing that your application catches real-time modifications easily. Whether it’s market prices, social media feeds, or live news, the Scraper API adapts to the ever-changing nature of the web.
- Timely Decision-Making The immediate availability of real-time data obtained via a Scraper API is critical for making fast decisions. Businesses, financial institutions, and numerous industries rely on fast access to information to make educated and strategic decisions based on the most recent data available. The API guarantees that decision-makers have the most recent information at their fingertips.
- Scalability & Efficiency Scraper APIs are intended to handle large-scale data extraction effectively. Whether you’re scraping data from a single webpage or numerous sources simultaneously, the API’s scalability allows you to retrieve real-time data quickly and effectively. This efficiency is beneficial when dealing with large amounts of continually changing information.
- Proxy and CAPTCHA Handling: Scraper APIs frequently incorporate proxy management tools to help prevent IP blocks and improve anonymity. This function allows users to cycle IP addresses, reducing the likelihood of being blacklisted by the target website. Furthermore, the API may include techniques to handle CAPTCHAs, allowing continuous data extraction even when confronted with difficulties meant to discourage automated scraping.
Conclusion
A real-time data API is a useful tool for individuals who want to get the most recent data fast and easily. It is a specialized tool that can swiftly and efficiently collect website data. Digital Elliptical facilitates hassle-free real-time data scraping since the scraper API is efficient, can manage a wide range of website material, and can scale up to handle massive volumes of data.
However, it is vital to recall the guidelines and restrictions for using this equipment. Each website has its own set of terms and conditions, and following them is necessary for utilizing the Scraper API responsibly and ethically. Real-time data APIs are gaining popularity as the demand for up-to-date data develops.